
DeepSeek无显卡本地部署70B,能跑吗?
![]() 波导终结者
2025-03-21 15:54
波导终结者
2025-03-21 15:54
大家好,我是波导终结者。

在我写这篇文章的这几天,号称32B能媲美DeekSeek-R1满血671B的QwQ模型已经放出来了,我还没有完成完整的测试。今天先把前不久折腾的llama-70B本地部署整理出来与大家分享。因为之前有小伙伴留言,说70B也是能跑的,慢点是慢点,自己本地折腾个乐呵。我想一想也有道理,但是具体什么样才叫“能”跑,定义可能不一样。最基础的,能载入运行,不崩,能正确出结果,再慢也叫能跑。那咱们就以这个定义为基础,来看看本地无显卡部署DeepSeek是否可行吧?
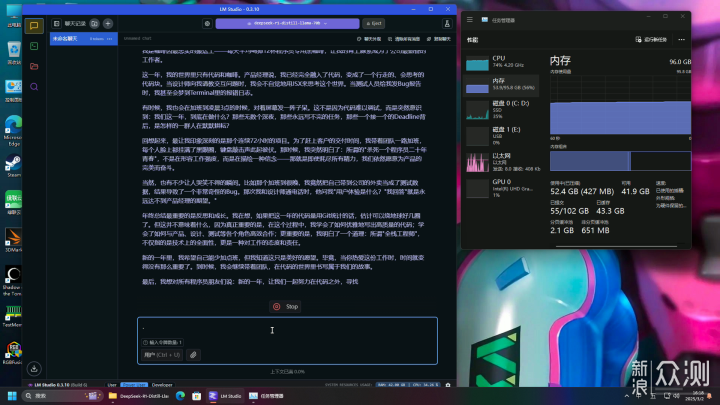
70B-Q4_K_M的模型大小为42.52GB,基本上得64G内存才有戏,出于谨慎起见,这里我还是放到96G的机子上跑。而Q6模型有57.88G,Q8模型有74.98G,根据自己机子酌情选择。CPU线程池拉满,评估处理大小拉到1024,题目为“请帮我写一篇年终总结,主角是程序员,每天工作24小时,每周工作6天”。实测CPU占用50-70%左右,双通道内存仍存在瓶颈但并未达到质变程度,内存占用54GB左右。4分43秒出结果,1.64 tok/sec,1233 tokens,6.79s to first token,还算可以接受。
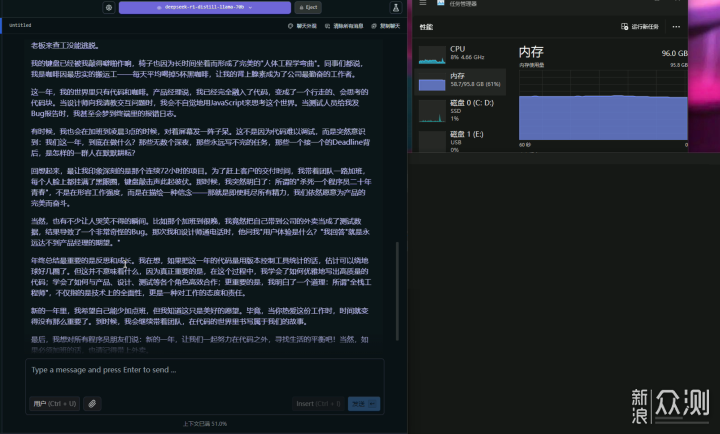
但根据小伙伴反馈,70B在连续对话时会卡住。这里我测试了一下,要求继续在原文基础上修改。原文有“一天12杯黑咖啡”,“梦到Terminal里的报错日志”,“公司attendance系统”,“用JSX来思考这个世界”这样不合理,或者无必要英文的使用。我跟它说,“一天喝12杯咖啡会死人的,没必要的英文请改成中文”。此时,小伙伴所反馈的疑似卡住的现象开始出现,虽然显示4分24秒出结果,但是1.61 tok/sec,1183 tokens,1050.18s to first token。注意这个first token,换算一下,它先思考了17.5分钟,才开始正式工作。总的等待时间已经超过20分钟。
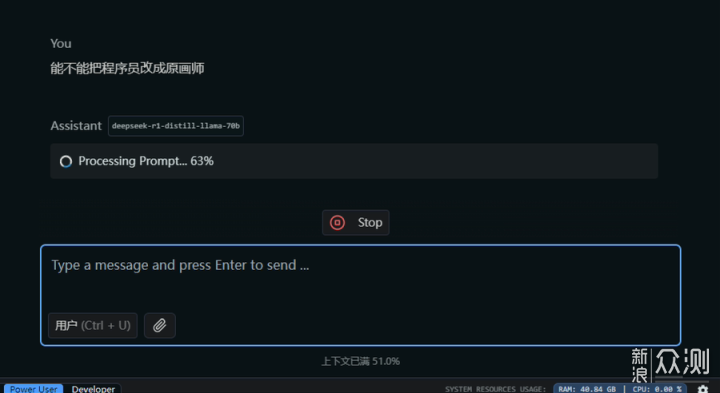
但你说它能跑吗?确实能跑,结果也很不错。没有必要的英语单词都换成了中文术语,“BUG,Deadline”等可以保留的都保留了,“JSX来思考世界”改成了“JavaScript来思考世界”。其他部分没有叫它改的,也都没有乱改。只是程序也好AI也好,思考方式和人类还是有区别,才会需要把之前的内容都回锅一遍吧。这里我叫它把程序员改成原画师,正式计算结果之前又卡住好久。
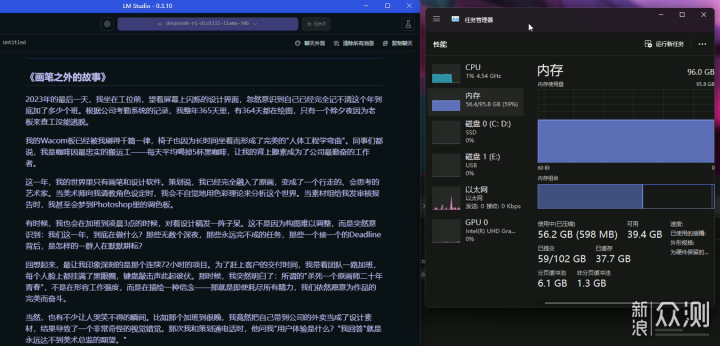
随着负载的加重,出结果的速度继续变慢。5分19出结果,1.58 tok/sec,1239 tokens,1162.05s to first token,还不知道之前的Processing Prompt有没有算进去。结果倒是中规中矩,文章架构几乎没换,只是把一些描述和字眼,从程序员相关,换成了画师相关。

总的来看,本地部署70B,只要内存够,上下文不爆炸,慢是慢了点,倒也不能说不能用。至于最近冒出来的QwQ-32B,测试完再跟大家分享。
感谢大家的观看,点赞和关注,我们下期再见。

关注官方微博 微博
关注官方微信

Copyright © 1996-2025 SINA Corporation, All Rights Reserved 新浪公司 版权所有










